Introduction
En production, les problèmes réseau sont parmi les plus délicats. Lorsqu’un service devient intermittent, comment mener l’investigation ? S'agit‑il d’une mauvaise configuration de la carte réseau ? De paramètres noyau inadaptés ? De plusieurs interfaces avec ou sans bonding ? L’environnement réseau complexe peut vite désorienter. Cet article compile des scénarios typiques rencontrés en administration et détaille la démarche de diagnostic.
Phénomène observé
Les symptômes suivants peuvent tous être abordés avec la même méthode générique de diagnostic : perte de paquets sur le serveur, connexion réseau intermittente, temps de réponse Ping irrégulier, trafic entrant normal mais échec du trafic sortant, etc. Il suffit ensuite d’affiner l’analyse en fonction de votre environnement.
Outils de diagnostic et études de cas
Commençons par comprendre le cheminement d’un paquet depuis la carte réseau jusqu’à l’application.
Le flux de base est le suivant :
Paquet entrant sur la carte réseau → Cache matériel FIFO → Tampon du pilote (Ring Buffer) → Tampon de traitement de la pile réseau (sk_buff) → Tampon de couche transport (fenêtre de réception TCP/UDP) → File d’attente de réception du socket → Tampon de l’application utilisateur.
Diagramme synthétique :
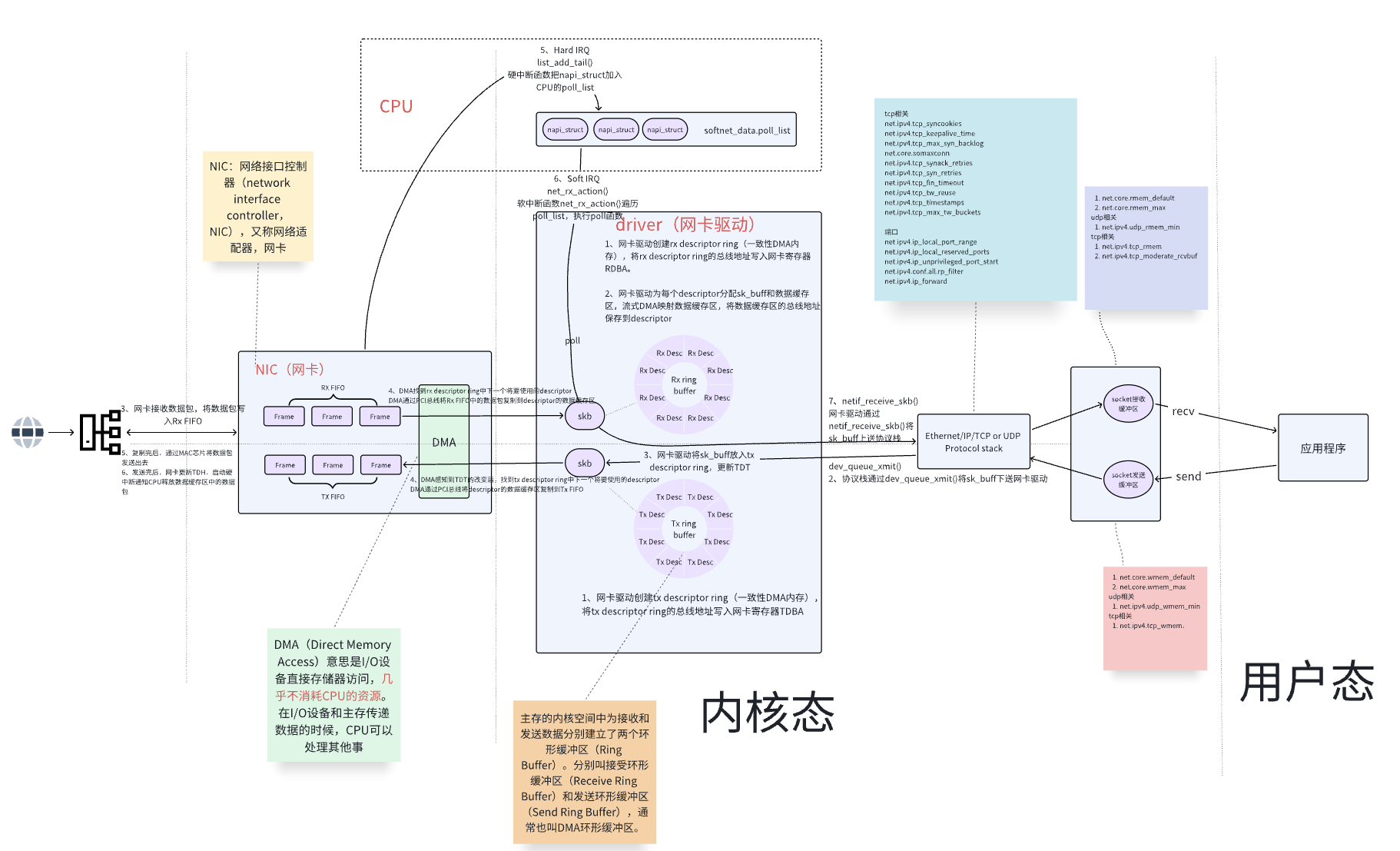
Le paquet arrive d’abord dans le cache FIFO de la carte, puis est transféré par DMA vers le tampon skb pointé par le Ring Buffer (une structure contenant les données et les métadonnées du paquet, le sk_buff). Ceci déclenche une interruption matérielle sur le CPU. Ensuite, la pile de protocoles (TCP/IP) prend le relais : le noyau extrait le skb du Ring Buffer, ajuste les pointeurs et l’envoie vers le tampon de la couche transport, puis dans la file d’attente de réception du socket. Finalement, l’application appelle recv() pour récupérer le paquet.
Présentation des outils de diagnostic
Outils au niveau de la carte réseau
-
ifconfig# ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.0.100 netmask 255.255.255.0 broadcast 10.0.0.255 inet6 fe80::7693:5725:5504:e974 prefixlen 64 scopeid 0x20<link> ether 1c:83:41:93:20:46 txqueuelen 1000 (Ethernet) RX packets 271922 bytes 29995005 (28.6 MiB) RX errors 0 dropped 3396 overruns 0 frame 0 TX packets 325387 bytes 132126535 (126.0 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 device interrupt 94Les indicateurs importants pour la réception sont errors, dropped et overrusn.
- RX errors : nombre total d’erreurs de réception (trames trop longues, erreurs CRC, erreurs de synchronisation, FIFO overruns, paquets manqués, etc.).
- RX dropped : paquets qui ont atteint le Ring Buffer mais ont été abandonnés lors de la copie vers la mémoire (manque de mémoire, etc.).
- RX overruns : débordement du FIFO causé par un taux d’entrée supérieur à ce que le noyau peut traiter. Les paquets sont rejetés avant même d’entrer dans le Ring Buffer, souvent parce que le CPU n’a pas traité les interruptions assez vite.
-
Fichier
/proc/net/dev# cat /proc/net/dev Inter-| Receive | Transmit face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed lo: 176076 472 0 0 0 0 0 0 176076 472 0 0 0 0 0 0 eth0: 30638495 276730 0 3620 0 0 0 49 132188337 326011 0 0 0 0 0 0 docker0: 2367947 283 0 0 0 0 0 0 65366 393 0 0 0 0 0 0Il faut surveiller errs, drop et fifo. La différence principale :
- drop : le paquet est entré dans le FIFO de la carte et a déclenché une interruption, mais il a été perdu lors de la copie vers la mémoire (ressources système insuffisantes).
- fifo : le paquet a été perdu avant même d’entrer dans le FIFO, car celui‑ci était plein. Cela indique que le système était trop occupé pour répondre aux interruptions. Il faut alors vérifier la charge CPU et la distribution des interruptions.
-
ethtool -S# ethtool -S eth0 | grep -iE 'error|drop' tx_underflow_errors: 0 tx_carrier_error_frames: 0 tx_excessive_deferral_error: 0 rx_crc_errors: 0 rx_align_error: 0 rx_crc_errors_small_packets: 0 rx_crc_errors_giant_packets: 0 rx_length_errors: 0 rx_out_of_range_errors: 0 rx_fifo_overflow_errors: 0 rx_watchdog_errors: 0 rx_receive_error_frames: 0 fatal_bus_error: 0Les paramètres clés sont
rx_length_errors,rx_out_of_range_errorsetrx_fifo_overflow_errors. -
netstat -ietnetstat -s# netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg docker0 1500 786339 0 0 0 1440038 0 0 0 BMRU eth0 1500 3999545 18446744073709551615 4805 0 2278246 0 0 0 BMRU lo 65536 774 0 0 0 774 0 0 0 LRUStatistiques par protocole :
# netstat -s
Outils au niveau du noyau
-
ssetnetstatAfficher tous les sockets en écoute (TCP/UDP) :
# ss -tnlp # ss -unlp State Recv-Q Send-Q Local Address:Port Peer Address:Port ProcessAfficher tous les sockets :
# ss -an Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port # netstat -anp Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Active UNIX domain sockets (servers and established) Proto RefCnt Flags Type State I-Node PID/Program name PathLa sortie de
netstatse divise en deux parties :- Active Internet connections : connexions réseau.
- Active UNIX domain sockets : communication locale, plus performante.
Partie Active Internet connections :
- Proto : protocole (TCP, UDP, TCP6, UDP6).
- Recv-Q (hors état LISTEN) : données non encore lues par l’application (appel
recv()). Une valeur élevée persistante peut indiquer une attaque DoS. - Send-Q (hors état LISTEN) : données non encore acquittées par le distant. Si la file ne se vide pas, l’application envoie trop vite ou le récepteur est lent. Un grand nombre de Send-Q peut être dû à un trop grand nombre de connexions persistantes.
- Local Address : adresse et port locaux.
- Foreign Address : adresse et port distants.
- State : état de la connexion TCP.
- PID/Program name : processus utilisant la connexion.
En état LISTEN, Recv‑Q et Send‑Q ont une signification différente :
- Recv-Q : nombre de connexions en attente d’acceptation (backlog).
- Send-Q : valeur maximale du backlog (paramètre
listen).
Partie Active UNIX domain sockets :
- RefCnt : nombre de processus attachés au socket.
- Flags : SO_ACCEPTON (socket en attente de connexion).
- Type : SOCK_DGRAM, SOCK_STREAM, SOCK_RAW, SOCK_RDM, SOCK_SEQPACKET, SOCK_PACKET.
- State : FREE, LISTENING, CONNECTING, CONNECTED, DISCONNECTING, empty.
- I-Node : nœud d’inode du fichier.
- Path : chemin du processus lié au socket.
-
sysctl: visualisation et modification des paramètres noyau. -
perf+ftrace: analyse des performances du noyau.Scénario Commande exemple Surveillance temps réel des interruptions sudo perf top -e irq:irq_handler_entryStatistiques des interruptions sudo perf stat -e irq:* -a sleep 10Enregistrement des appels de pile sudo perf record -e irq:irq_handler_entry -g -a -- sleep 30Génération d’une flamegraph perf scriptCompteur d’interruptions système watch -n 1 "cat /proc/interrupts"
Études de cas
Analyse de la latence ping
Phénomène
En situation de stress, la latence réseau devient instable (ping élevé) alors qu’elle est normale sans charge.
Démarche
Examen du CPU
Utilisez lscpu pour connaître le nombre de cœurs, les nœuds NUMA, etc.
# lscpu
Architecture : aarch64
CPU op-mode(s) : 64-bit
Endian : Little Endian
CPU : 128
Liste des CPU en ligne : 0-127
Thread(s) par cœur : 1
Cœur(s) par socket : 64
Socket(s) : 2
Nœud(s) NUMA : 4
Identifiant constructeur : HiSilicon
...
Affinité NUMA de la carte réseau
# cat /sys/class/net/enp0s1f0/device/numa_node
0
La carte est attachée au nœud NUMA 0 (CPU 0-31).
Affinité CPU de la carte
cat /sys/class/net/enp0s1f0/device/local_cpulist
0-31
Utilisation CPU et charge
Utilisez top, ps pour évaluer la charge.
Files d’attente de la carte réseau (queues)
La technique multi‑files (RSS) répartit les interruptions sur plusieurs cœurs, améliorant les performances PPS et le débit. Comparé à une file unique, deux files peuvent doubler les performances.
# ethtool -l enp0s1f0
Channel parameters for enp0s1f0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 1
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 1
Ici une seule file est active. Deux cas : la carte est mono‑file, ou la configuration BIOS n’a activé qu’une file. Pour vérifier si la carte supporte plusieurs files :
# ethtool -i enp0s1f0
driver: hns3
version: ...
bus-info: 0000:7d:00.0
# lspci -vvv | grep -A 80 '7d:00.0' | grep -i msi-x
Capabilities: [a0] MSI-X: Enable+ Count=131 Masked-
Le compteur Count=131 indique un support multi‑file. Si une seule file apparaît, vérifiez le BIOS.
Taille du Ring Buffer
# ethtool -g enp0s1f0
Ring parameters for enp0s1f0:
Pre-set maximums:
RX: 32760
TX: 32760
Current hardware settings:
RX: 1024
TX: 1024
Vérification des pertes
# ifconfig enp0s1f0
Dans ce cas, il n’y a que de la latence, pas de perte. L’accent doit donc être mis sur les ressources CPU et la distribution des interruptions.
Analyse des interruptions
# grep hns3-0000:7d:00.0 /proc/interrupts
...
263: 0 ... 781452 ... 0 ... ITS-MSI 65536001 Edge hns3-0000:7d:00.0-TxRx-0
Pour connaître le CPU qui traite une interruptoin donnée, utilisez /proc/irq/263/smp_affinity :
cat /proc/irq/263/smp_affinity
00000000,00000000,00000000,00080000
Convertissez en binaire : 00080000 hex → 0000 0000 0000 1000 0000 0000 0000 0000 binaire. Le bit à 1 est le 20e en partant de la droite (CPU 19).
Solutions
La latence sans perte et sans problème TCP suggère une saturation des ressources d’interruption ou un retard d’ordonnancement noyau.
Manque de ressources CPU
Vérifiez si le CPU 19 (ou celui qui gère l’interruption) est très utilisé. Si oui, activez les multi‑files de la carte pour répartir la charge.
Pour notre exemple (serveur Kunpeng 920) : accédez au BIOS → Advanced → Lom Configuration → NIC Configuration → Port1 Configuration → modifiez Tqp Number à 60 (ou toute valeur) → sauvegardez.
# ethtool -l enp0s1f0
Channel parameters for enp0s1f0:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 60
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 60
Réduisez le nombre de files à 32 pour qu’elles correspondent aux 32 CPU du nœud NUMA 0 :
# ethtool -L enp0s1f0 combined 32
# grep hns3-0000:7d:00.0 /proc/interrupts | wc -l
32
Vous pouvez aussi assigner manuellement chaque file à un CPU via /proc/irq/.../smp_affinity.
Retard d’ordonnancement noyau
Si le CPU n’est pas saturé, un processus peut monopoliser la ressource ou un lock doux empêche l’ordonnancement. Utilisez perf sched pour détecter les délais :
perf sched record -aT sleep 10
perf sched latency -s max
Une latence de plusieurs secondes pour le thread ksoftirqd indique que l’interruption logicielle (softirq) est retardée. Dans ce cas, le paquet a été mis en file d’attente mais la softirq n’a été exécutée qu’après un long délai, causant la latence ping. La cause racine est souvent un processus récalcitrant ou un verrou non préemptible. Il faut alors analyser plus finement avec des flamegraphs et éventuellement le code source du noyau.
Analyse des pertes de paquets
Phénomène
Des paquets sont perdus en émission ou réception sur la carte réseau, ou au niveau des applications.
Démarche
Les outils mentionnés en début d’article (ifconfig, ethtool, /proc/net/dev, ss) permettent déjà de localiser l’étape où se produisent les pertes. Une fois identifiée, on optimise cette étape.
Solutions
Débordement du Ring Buffer
Le Ring Buffer a une taille limitée. Si le taux de réception dépasse la capacité de traitement du CPU, il se remplit et les nouveaux paquets sont rejetés.
-
Capacité d’interruption insuffisante : si la carte est mono‑file et le trafic intense, les interruptions ne sont pas traitées assez vite. Activez les multi‑files comme décrit précédemment.
-
Taille du Ring Buffer trop petite : augmentez‑la avec
ethtool -G.# ethtool -G enp0s1f0 rx 4096 tx 4096 # ethtool -g enp0s1f0 Current hardware settings: RX: 4096 TX: 4096
Débordement de netdev_max_backlog
Le fichier /proc/net/softnet_stat enregistre par CPU le nombre de paquets traités, perdus, etc. La deuxième colonne (hexadécimale) indique le nombre de paquets abandonnés par dépassement de netdev_max_backlog.
# cat /proc/net/softnet_stat
00120244 00000000 ...
0013df4c 00000000 ...
Si cette colonne n’est pas nulle, augmentez net.core.netdev_max_backlog :
sysctl -w net.core.netdev_max_backlog=16384
Budget de softirq (netdev_budget)
Si la troisième colonne de softnet_stat augmente, le temps CPU alloué aux softirq est insuffisant. Réduisez alors net.core.netdev_budget ou augmentez le temps (netdev_budget_usecs).
# sysctl net.core.netdev_budget
net.core.netdev_budget = 1024
Une valeur trop petite entraîne plus de softirq, ce qui augmente la charge CPU et aggrave le problème.
Débordement des tampons TCP/UDP / Socket
Chaque socket possède un tampon de lecture et d’écriture. Les paramètres noyau associés sont :
# sysctl -a | grep mem
net.core.optmem_max = 524288
net.core.rmem_default = 2097152
net.core.rmem_max = 16777216
net.core.wmem_default = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_mem = 180486 240648 360972
net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_mem = 360972 481297 721944
net.ipv4.udp_rmem_min = 4096
net.ipv4.udp_wmem_min = 4096
TCP : grâce au contrôle de flux (fenêtre glissante), un tampon plein n’entraîne pas de perte mais un ralentissement (indiqué par window zero dans une capture).
UDP : les pertes peuvent être détectées dans /proc/net/udp (colonne drops) et /proc/net/snmp (champs InErrors et RcvbufErrors). Si ces deux valeurs sont proches, la cause est presque certainement une file de réception socket saturée. Augmentez alors rmem_max et rmem_default, ou optimisez l’application.
Débordement des files d’attente semi‑ouverte (SYN) et complète (Accept)
Lors de l’établissement TCP :
- File SYN (contrôlée par
net.ipv4.tcp_max_syn_backlog) : stocke les connexions avant la fin du three‑way handshake. Si elle est pleine, les nouvelles tentatives sont rejetées. - File Accept (contrôlée par
net.core.somaxconn) : stocke les connexions complètement établies en attente deaccept(). Si pleine, le serveur envoie unConnection refused.
Augmentez ces valeurs si nécessaire.
Perte liée à la segmentation / réassemblage (TSO/GSO, LRO/GRO)
TSO/GSO (émission) : permettent de décharger la segmentation TCP/UDP sur la carte réseau. Ils réduisent la charge CPU.
LRO/GRO (réception) : regroupent plusieurs paquets en un pour alléger la pile réseau.
# ethtool -k enp0s1f0 | grep -E "tcp-segmentation-offload|generic-segmentation-offload"
tcp-segmentation-offload: on
generic-segmentation-offload: on
# ethtool -k enp0s1f0 | grep offload
generic-receive-offload: on
large-receive-offload: off [fixed]
Un déséquilibre entre TSO (émission) et LRO (réception) peut provoquer des pertes asymétriques. Par exemple, si la carte ne supporte que l’un des deux, le débit de paquets peut différer et saturer un tampon.
Activez ou désactivez ces fonctionnalités avec :
ethtool -K enp0s1f0 tso off # exemple
Problèmes de MTU / MSS / PMTU
MTU (Maximum Transmission Unit) : taille maximale d’un paquet au niveau de la couche liaison. Par défaut 1500 octets sur Ethernet.
# ip a
2: enp0s1f0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
# netstat -i
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
enp0s1f0 1500 13429030 0 444287 0 19834143 0 0 0 BMRU
Modification temporaire : ifconfig enp0s1f0 mtu 1200 ; permanente sous NetworkManager : nmcli connection modify enp0s1f0 +ethernet.mtu 1200.
MSS (Maximum Segment Size) : partie utile maximale d’un segment TCP (sans en‑tête IP/TCP). MSS = MTU - 40 (IPv4). UDP : MSS = MTU - 20.
Lors de la négociation TCP (trois‑way handshake), la valeur de MSS est échangée (visible dans une capture).
PMTU (Path MTU) : plus grande taille de paquet pouvant traverser le chemin réseau sans fragmentation. Le mécanisme PMTUd (activé par défaut quand net.ipv4.ip_no_pmtu_disc=0) évite la fragmentation.
Test avec ping -M do -s <size></size> :
# ping -c 3 -M do -s 1480 10.0.0.1
ping: local error: message too long, mtu=1500
Le paquet dépasse 1500 octets (20 IP + 8 ICMP + 1480 = 1508). En réduisant à 1472, ça passe :
# ping -c 3 -M do -s 1472 10.0.0.1
1480 bytes from 10.0.0.1: icmp_seq=1 ttl=63 time=0.783 ms
Pour verrouiller le MTU sur une route (exemple vers la passerelle) :
ip route add 0.0.0.0 via 192.168.18.252 mtu lock 1300