CenterNet est une architecture de détection d'objets "anchor-free" qui traite les objets comme des points uniques (leurs centres). Cette approche simplifie considérablement le pipeline de détection par rapport aux méthodes traditionnelles basées sur les boîtes d'ancrage. Nous allons ici explorer une implémentation optimisée de CenterNet, basée sur pytorch_simple_CenterNet_45, qui offre une meilleure lisibilité du code et des performances accrues par rapport à la version officielle.
1. Préparation de l'environnement
Pour débuter, assurez-vous de disposer de la configuration suivante :
- Python >= 3.5
- PyTorch (versions 0.4.1, 1.0.0 ou 1.1.0 testées)
- TensorboardX (pour le monitoring)
Configuration de base
Une optimisation spécifique consiste à désactiver le Batch Normalization de cuDNN. Dans votre installation de PyTorch, modifiez le fichier torch/nn/functional.py en localisant l'appel à torch.batch_norm et en fixant torch.backends.cudnn.enabled = False.
Ensuite, récupérez le code source et installez les dépendances nécessaires :
# Installation de COCO API
cd $ROOT_DIR/lib/cocoapi/PythonAPI
make
python setup.py install --user
# Compilation des couches de convolution déformables (DCNv2)
# Choisissez la version correspondant à votre PyTorch (old pour 0.4.1, new pour 1.0+)
cd $ROOT_DIR/lib/DCNv2
./make.sh
# Compilation du NMS (Non-Maximum Suppression)
cd $ROOT_DIR/lib/nms
make
2. Adaptation du code à votre jeu de données
Bien que CenterNet utilise nativement le format COCO, nous allons configurer l'entraînement pour un format Pascal VOC personnalisé. Supposons que nous n'ayons qu'une seule classe nommée "cible".
Modification de la classe de données
Éditez le fichier datasets/pascal.py pour refléter vos catégories :
# Liste des classes (index 0 réservé au background)
CLASSES_VOC = ['__background__', 'cible']
# Mise à jour des paramètres dans le constructeur de la classe
self.num_classes = 1
self.valid_ids = np.arange(1, 2, dtype=np.int32)
Conversion des annotations XML en JSON
Comme l'implémentation attend du JSON (format COCO), nous devons convertir nos fichiers XML Pascal VOC. Voici un script optimisé pour cette tâche :
import xml.etree.ElementTree as ET
import os
import json
def convert_voc_to_coco(xml_dir, output_json):
coco_data = {
"images": [],
"annotations": [],
"categories": [],
"type": "instances"
}
label_map = {}
label_count = 0
ann_id_counter = 0
img_id_counter = 20240000
for file_name in os.listdir(xml_dir):
if not file_name.endswith('.xml'):
continue
tree = ET.parse(os.path.join(xml_dir, file_name))
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
img_id_counter += 1
image_info = {
"file_name": file_name.replace('.xml', '.jpg'),
"id": img_id_counter,
"width": w,
"height": h
}
coco_data["images"].append(image_info)
for obj in root.findall('object'):
label_name = obj.find('name').text
if label_name not in label_map:
label_count += 1
label_map[label_name] = label_count
coco_data["categories"].append({
"id": label_count,
"name": label_name,
"supercategory": "none"
})
bbox = obj.find('bndbox')
x1 = int(bbox.find('xmin').text)
y1 = int(bbox.find('ymin').text)
x2 = int(bbox.find('xmax').text)
y2 = int(bbox.find('ymax').text)
bw, bh = x2 - x1, y2 - y1
ann_id_counter += 1
annotation = {
"id": ann_id_counter,
"image_id": img_id_counter,
"category_id": label_map[label_name],
"bbox": [x1, y1, bw, bh],
"area": bw * bh,
"iscrowd": 0,
"segmentation": [[x1, y1, x1, y2, x2, y2, x2, y1]]
}
coco_data["annotations"].append(annotation)
with open(output_json, 'w') as f:
json.dump(coco_data, f)
if __name__ == '__main__':
convert_voc_to_coco('./data/voc/xml_labels', './data/voc/annotations/pascal_train.json')
3. Structure des fichiers
Organisez vos données selon l'arborescence suivante pour assurer la compatibilité avec le dataloader :
data/
└── voc/
├── annotations/
│ ├── pascal_train.json
│ └── pascal_val.json
├── images/
│ └── *.jpg
└── VOCdevkit/
└── VOC2007/
├── Annotations/ (*.xml)
├── JPEGImages/ (*.jpg)
└── ImageSets/Main/ (train.txt, val.txt)
4. Lancement de l'entraînement
Le script d'entraînement accepte divers paramètres pour configurer le backbone et les hyperparamètres. Voici une commande type utilisant un ResNet-18 avec convolutions déformables :
python train.py --dataset pascal \
--arch resdcn_18 \
--img_size 384 \
--lr 1.25e-4 \
--batch_size 32 \
--num_epochs 70 \
--lr_step 45,60 \
--log_name my_custom_model
Les architectures disponibles incluent resdcn_18, resdcn_50, et large_hourglass. Le paramètre img_size doit être cohérent entre l'entraînement et l'inférence.
5. Évaluation et Résultats
Pour tester votre modèle sur le jeu de validation, utilisez le script de test. L'activation du mode "flip test" peut améliorer la précision (mAP) :
python test.py --dataset pascal \
--arch resdcn_18 \
--img_size 384 \
--log_name my_custom_model \
--test_flip
En suivant cette procédure sur un jeu de données spécifique, il est courant d'atteindre une précision moyenne (mAP) supérieure à 90%, selon la complexité des images et la qualité des annotations.
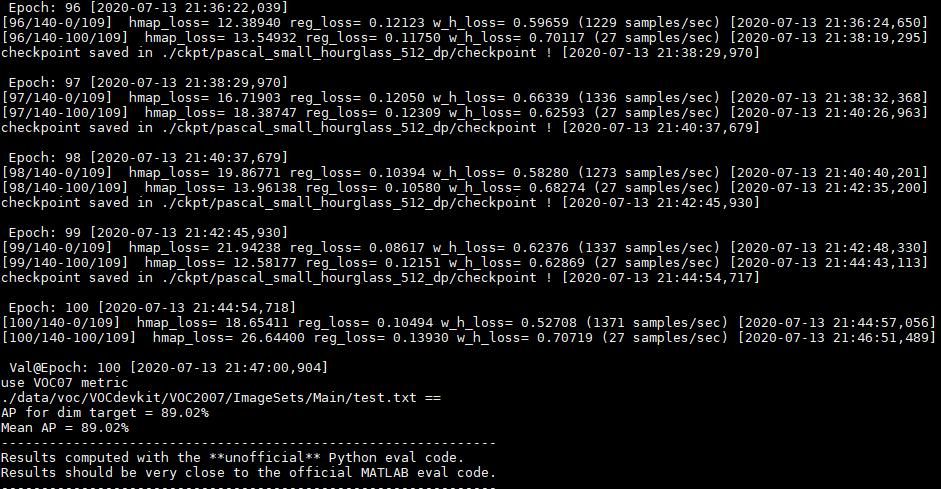 Chaque cycle d'entraînement peut être monitoré via Tensorboard pour observer la convergence des différentes pertes (heatmap loss, size loss et offset loss).
Chaque cycle d'entraînement peut être monitoré via Tensorboard pour observer la convergence des différentes pertes (heatmap loss, size loss et offset loss).