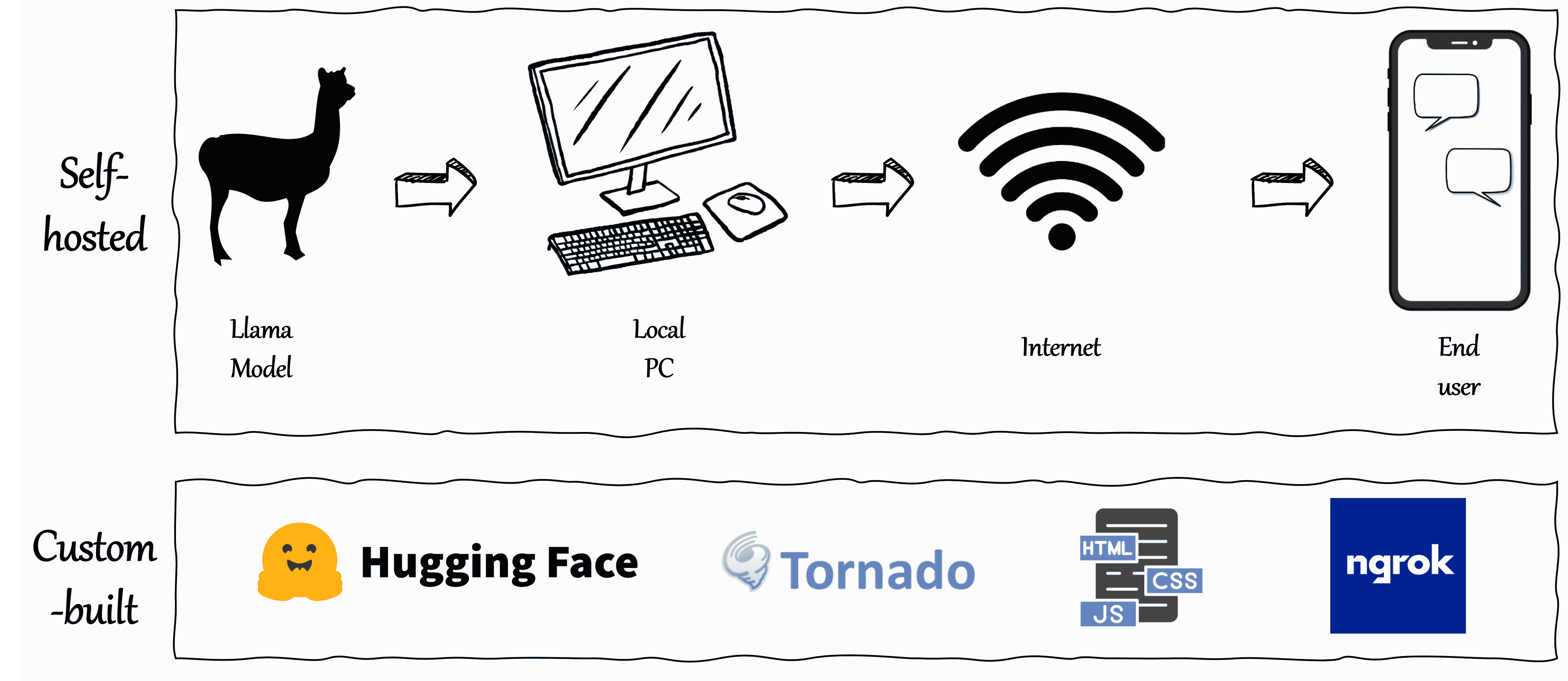
Plusieurs approches existent pour développer des applications basées sur des modèles de langage:
1. Plateformes cloud
Soltuions comme GPT-4 ou Huggingface Space présentent des limites :
- Problèmes de confidentialité des données
- Latence liée aux ressources partagées
- Coûts des appels d'API
2. Applications autogérées
Solutions clés en main comme Ollama+OpenWebUI simplifient le déploiement mais manquent de flexibilité pour des personnalisatinos avancées.
3. Applications personnalisées
Notre solution combine des composants sur mesure pour un contrôle total du flux de traitement.
 ### Étapes de développement
### Étapes de développement
1. Modèle LLM avec Huggingface
Chargement du modèle Llama-3-8B avec quantification 4-bit :
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
modele_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokeniseur = AutoTokenizer.from_pretrained(modele_id)
config_quant = BitsAndBytesConfig(load_in_4bit=True)
modele = AutoModelForCausalLM.from_pretrained(
modele_id,
device_map="auto",
torch_dtype=torch.bfloat16,
cache_dir="modeles",
quantization_config=config_quant
)
Fonction de génération avec gestion du contexte :
def generer_reponse(utilisateur_id, nouveau_message, historiques, tokeniseur, modele):
historique = historiques.get(utilisateur_id, [])
historique.append({"role": "utilisateur", "content": nouveau_message})
inputs = tokeniseur.apply_chat_template(
historique,
add_generation_prompt=True,
return_tensors="pt"
).to(modele.device)
try:
sorties = modele.generate(
inputs,
max_new_tokens=256,
do_sample=True,
temperature=0.6,
top_p=0.9,
eos_token_id=[tokeniseur.eos_token_id, tokeniseur.convert_tokens_to_ids("<|eot_id|>")]
)
reponse = tokeniseur.decode(sorties[0], skip_special_tokens=True)
reponse = reponse.split("assistantn")[-1].strip()
historique.append({"role": "system", "content": reponse})
historiques[utilisateur_id] = historique
return reponse
except Exception as e:
print(f"Erreur: {e}")
return "Erreur de traitement, veuillez réessayer"
2. Backend avec Tornado
Serveur web avec gestion des conversations :
import tornado.ioloop
import tornado.web
import json
historiques_conversations = {}
class GestionnairePrincipal(tornado.web.RequestHandler):
def get(self):
self.render("web/index.html")
class GestionnaireChat(tornado.web.RequestHandler):
def post(self):
donnees = json.loads(self.request.body)
reponse = generer_reponse(
donnees.get('user_id'),
donnees.get('message'),
historiques_conversations,
tokeniseur,
modele
)
self.write({'reponse': reponse})
def creer_app():
return tornado.web.Application([
(r"/", GestionnairePrincipal),
(r"/chat", GestionnaireChat),
(r"/(style.css)", tornado.web.StaticFileHandler, {"path": "web/"}),
(r"/(script.js)", tornado.web.StaticFileHandler, {"path": "web/"})
])
if __name__ == "__main__":
app = creer_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
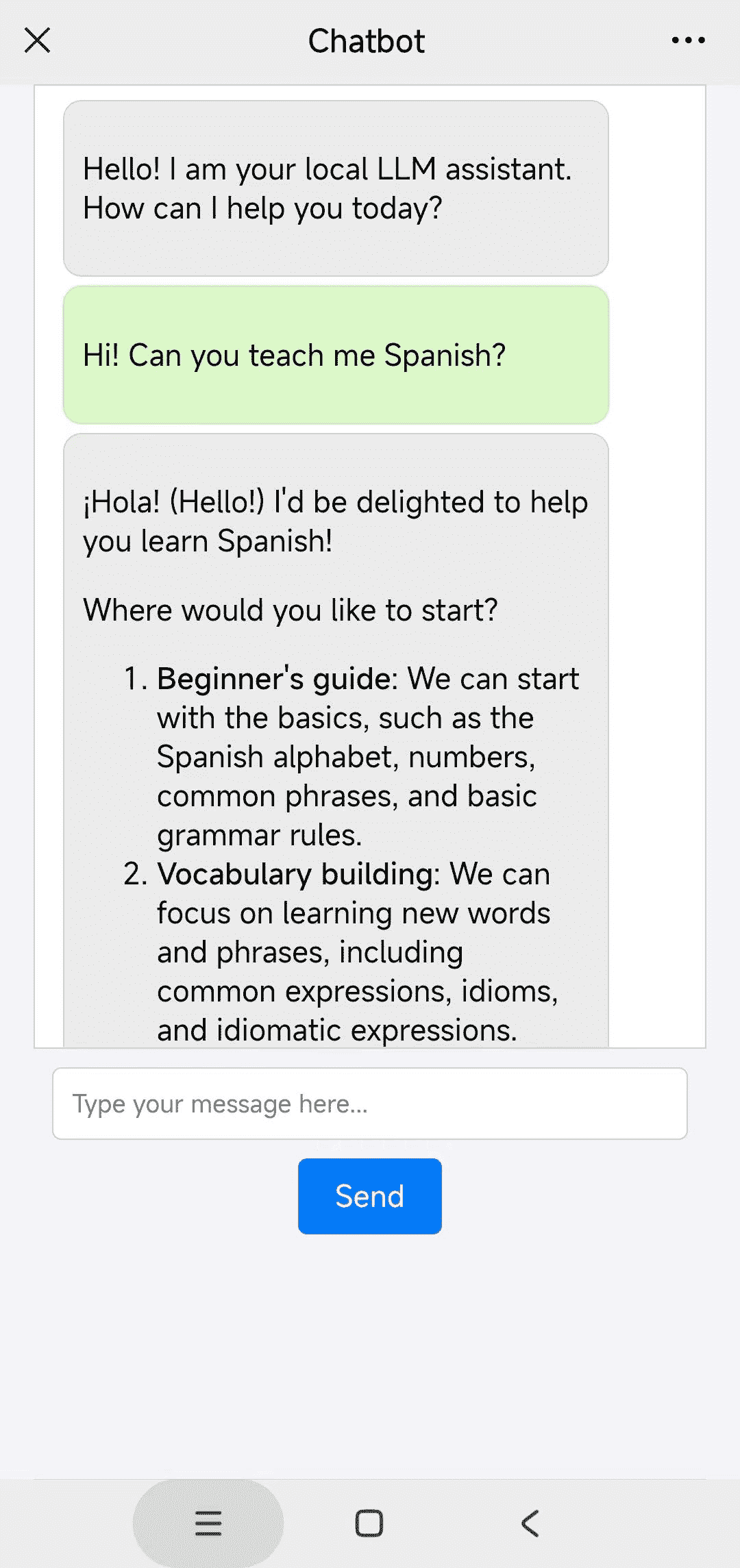
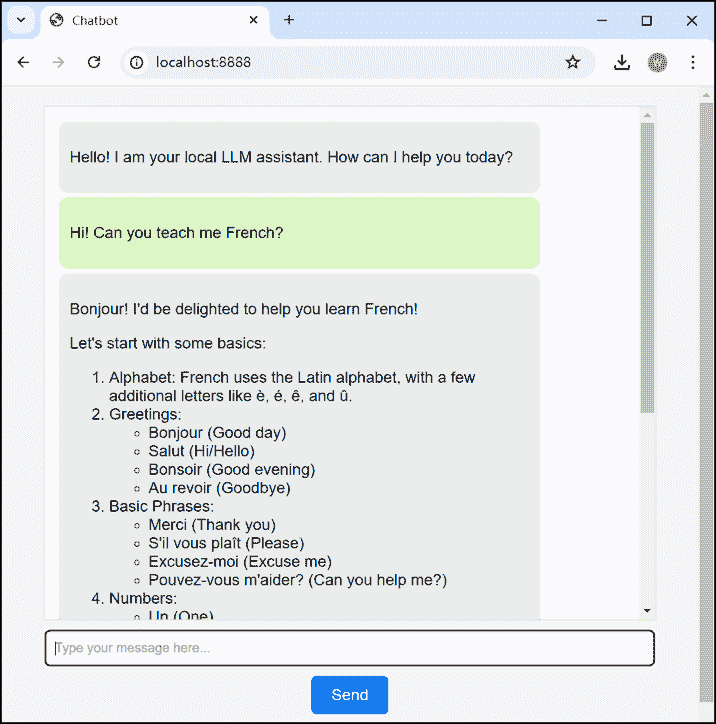
3. Interface utilisateur
Structure HTML de base :
<html>
<head>
<meta charset="UTF-8">
<title>Assistant Local</title>
<link rel="stylesheet" href="style.css">
<script src="https://cdn.jsdelivr.net/npm/showdown/dist/showdown.min.js"></script>
</head>
<body>
<div class="conteneur-chat">
<div id="boite-chat"></div>
<input type="text" id="saisie_utilisateur" placeholder="Votre message..." autofocus>
<button onclick="envoyerMessage()">Envoyer</button>
</div>
<script src="script.js"></script>
</body>
</html>
Fonctions JavaScript essentielles :
function obtenirIdUtilisateur() {
let id = localStorage.getItem('user_id')
if (!id) {
id = 'uid' + Math.random().toString(36).substr(2, 9)
localStorage.setItem('user_id', id)
}
return id
}
function envoyerMessage() {
const saisie = document.getElementById("saisie_utilisateur")
const message = saisie.value.trim()
const userId = obtenirIdUtilisateur()
if (message === "") return
ajouterMessage(message, "message-utilisateur")
fetch('/chat', {
method: 'POST',
body: JSON.stringify({ 'user_id': userId, 'message': message}),
headers: {'Content-Type': 'application/json'}
}).then(reponse => reponse.json())
.then(donnees => {
ajouterMessage(donnees.reponse, "message-systeme")
}).catch(erreur => {
console.error('Erreur:', erreur)
})
saisie.value = ""
}
 #### 4. Exposition publique avec Ngrok
#### 4. Exposition publique avec Ngrok
Étapes de déploeiment :
ngrok config add-authtoken <votre_token>
ngrok http http://localhost:8888